
This isn’t just an incremental upgrade. YOLO11 represents a significant leap forward, promising to redefine what’s possible in AI-powered vision
YOLO11 is the latest iteration in the Ultralytics YOLO series of real-time object detectors, redefining what’s possible with cutting-edge accuracy, speed, and efficiency. Building upon the impressive advancements of previous YOLO versions, YOLO11 introduces significant improvements in architecture and training methods, making it a versatile choice for a wide range of computer vision tasks.
This model can do a lot of cool things, like:
- Finding objects: It can locate and identify different objects in an image, like cars, people, or trees.
- Classifying things: It can tell you what kind of object it sees, like a cat or a banana.
- Understanding the shape of objects: It can even outline an object’s exact shape, like tracing it out.
- Figuring out poses: It can understand the position of a person’s body, such as whether they’re standing, sitting, or waving.
Key Features
- Enhanced Feature Extraction: YOLO11 employs an improved backbone and neck architecture, which enhances feature extraction capabilities for more precise object detection and complex task performance.
- Optimized for Efficiency and Speed: YOLO11 introduces refined architectural designs and optimized training pipelines, delivering faster processing speeds and maintaining an optimal balance between accuracy and performance.
- Greater Accuracy with Fewer Parameters: With advancements in model design, YOLO11m achieves a higher mean Average Precision (mAP) on the COCO dataset while using 22% fewer parameters than YOLOv8m, making it computationally efficient without compromising accuracy.
- Adaptability Across Environments: YOLO11 can be seamlessly deployed across various environments, including edge devices, cloud platforms, and systems supporting NVIDIA GPUs, ensuring maximum flexibility.
- Broad Range of Supported Tasks: Whether it’s object detection, instance segmentation, image classification, pose estimation, or oriented object detection (OBB), YOLO11 is designed to cater to a diverse set of computer vision challenges.
Dataset Information
The American Sign Language (ASL) dataset used in this project was sourced from Roboflow Universe/duyguj/american-sign-language-letters. All images in the dataset were pre-labeled, ensuring accurate training data. Additionally, data augmentation techniques were applied within Roboflow to increase the variability of the dataset, improving the model’s generalization. Techniques such as flipping, rotation, and brightness adjustments were employed.
This dataset contains a total of 1224 images, which are split into three sets:
- Train Set: 1008 images (82%)
- Validation Set: 144 images (12%)
- Test Set: 72 images (6%)
Preprocessing:
- Auto-Orient: Applied to ensure the images are properly aligned.
- Resize: All images are resized to fit within 640x640 pixels.
Data Augmentation:
Each training example has two outputs due to augmentation, which include:
- Rotation: Between -15° and +15° to simulate different hand orientations.
- Exposure: Adjustments between -10% and +10% to account for varying lighting conditions.
- Blur: Up to 2px to simulate motion or camera blur.
This setup is intended to improve the model’s ability to generalize by exposing it to varied inputs.
Training Process
The YOLO11 model was fine-tuned on this ASL dataset to specialize in object detection for sign language. This training process included:
- Dataset Augmentation: Using Roboflow to enhance the dataset with transformations.
- Model Training: YOLOv11 was trained using this enhanced dataset, and the performance was validated using a separate validation dataset.
- Testing: After training, the model was tested on a dedicated test set to evaluate its ability to predict unseen data.
Performance and Observations
The final model was tested on random sign language images and videos to observe its real-world performance. The results showed promising outcomes for detecting different ASL signs in real-time, demonstrating the effectiveness of the YOLO11 architecture in handling complex, gesture-based tasks.
Lets Code!
Setup and Initialization
Access to GPU¶
We can use nvidia-smi command to do that. In case of any problems navigate to Edit -> Notebook settings -> Hardware accelerator, set it to GPU.
“note: this setting is for kaggle”
!pip install ultralytics supervision roboflow
from IPython import display
display.clear_output()
!pip install ultralytics --quiet
import ultralytics
ultralytics.checks()Load the Dataset¶
Configure API keys to Load the Dataset
To fine-tune YOLO11, you need to provide your Roboflow API key. Follow these steps:
- Go to your
Roboflow Settingspage. ClickCopy. This will place your private key in the clipboard. - In Colab, go to the left pane and click on
Secrets(🔑). Store Roboflow API Key under the nameROBOFLOW_API_KEY. - Roboflow: Go to your
Roboflow Dataset Download-> Select YOLO model -> SelectShow download code-> clickCopy. - In Colab: go to the left pane and click on
Secrets(🔑). Store the Roboflow API Key under a username. - In Kaggle: Go to
Add-ons→Secrets→Add Secret(🔑) and store your Kaggle API key and username.
# Save the API key in Kaggle
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("my_api_key")# Roboflow Dataset API Code
!pip install roboflow --quiet
from roboflow import Roboflow
rf = Roboflow(secret_value_0)
project = rf.workspace("duyguj").project("american-sign-language-letters-vouo0")
version = project.version(1)
dataset = version.download("yolov11")Model Training
# Changing to the working directory in Kaggle
%cd /kaggle/working
# Training the YOLO model
!yolo task=detect mode=train model=yolo11n.pt data=/kaggle/working/American-Sign-Language-Letters-1/data.yaml epochs=10 imgsz=640 plots=True
#Results saved to runs/detect/train
#Learn more at https://docs.ultralytics.com/modes/trainfrom IPython.display import Image as IPyImage
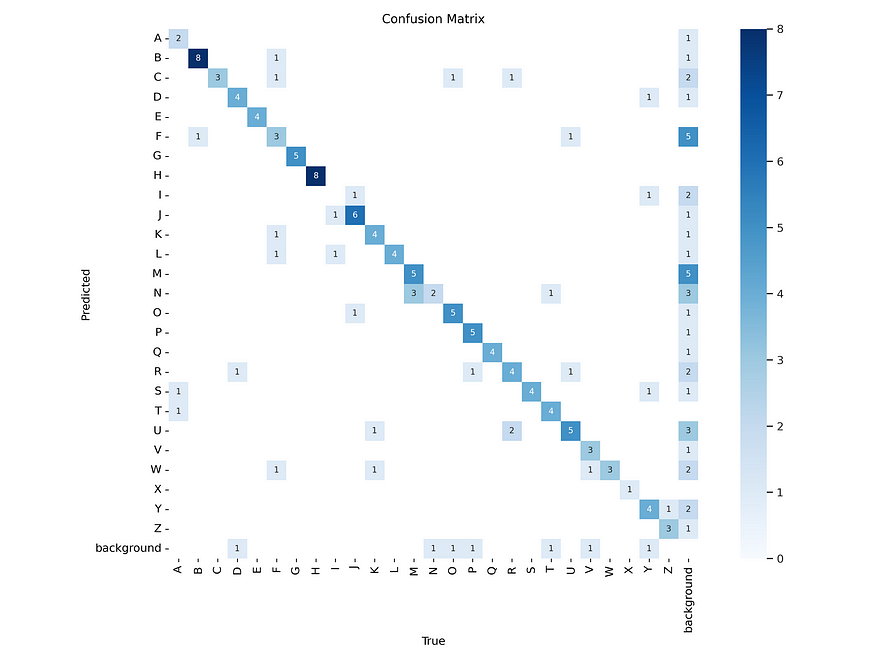
# Display the confusion matrix image from the specified directory in Kaggle
IPyImage(filename='/kaggle/working/runs/detect/train/confusion_matrix.png', width=1000)Output:
IPyImage(filename=f'/kaggle/working/runs/detect/train/results.png', width=1000)Output:

IPyImage(filename=f'/kaggle/working/runs/detect/train/val_batch0_pred.jpg', width=1000)Output:

Prediction
# Run the prediction task on Test Data
!yolo task=detect mode=predict model=/kaggle/working/runs/detect/train/weights/best.pt conf=0.25 source=/kaggle/working/American-Sign-Language-Letters-1/test/images save=True
#Results saved to runs/detect/predict
#💡 Learn more at https://docs.ultralytics.com/modes/predictPrediction with random images
import glob
import os
from IPython.display import Image as IPyImage, display
# Get the latest prediction folder for detection in Kaggle
latest_folder = max(glob.glob('/kaggle/working/runs/detect/predict*/'), key=os.path.getmtime)
# Display images from the prediction folder
for img in glob.glob(f'{latest_folder}/*.jpg')[15:18]:
display(IPyImage(filename=img, width=300))output:


Code source: kaggle