
Introduction:
Large Language Models (LLMs) are no longer science fiction. Artificial intelligence has developed a lot in recent times, with the rise of Large Language Models being one of the huge developments. TThese models are incredibly transformational across industry landscapes as they improve human-computer interactions, and explore new possibilities in technology.
In this blog post, we are going to demystify what LLMs involve and discuss how they execute various tasks. Consequently, We’ll also examine the benefits and challenges of LLMs and discuss their potential applications in various industries.
.png)
What are Large Language Models?
A large language model (LLM) is an algorithm that can perform a variety of natural language processing (NLP) tasks. Large language models (LLM) are very large deep learning models that are trained on vast amounts of text data to generate language outputs that are coherent and natural-sounding. They are called “large” because they have millions or even billions of parameters. LLMs are based on deep learning architectures, such as transformers, which allows them to learn and improve over time. They can write essays, answer questions, create content, and even hold conversations.
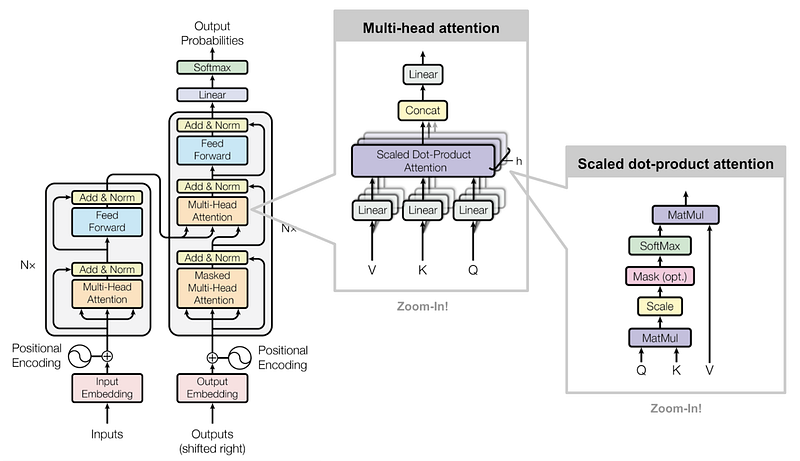
How do Large Language Models work?
LLMs work by using a technique called masked language modeling. In this approach, some of the words in the training text are randomly replaced with a [MASK] token, and the model is trained to predict the original word. This process is run millions of times, which allows for the model to understand patterns and relationships present in any language.
The training process involves several key steps:
- Data collection: A massive dataset of text is gathered from various sources, such as books, articles, and websites.
- Preprocessing: The text data is preprocessed to remove punctuation, convert to lowercase, and tokenize the text into individual words or subwords.
- Model training: The preprocessed data is fed into the LLM, which is trained to predict the original word for each [MASK] token.
- Model evaluation: The trained model is evaluated on a test dataset to measure its performance and accuracy.
What can Large Language Models do?
LLMs can do various tasks, including:
- Language translation: LLMs can translate text from one language to another with remarkable accuracy.
- Text summarization: LLMs can summarize long pieces of text into shorter, more digestible versions.
- Chatbots: LLMs can be used to power chatbots that can have natural-sounding conversations with humans.
- Content creation: LLMs can generate text, such as articles, stories, and even entire books.
- Sentiment analysis: LLMs can analyze text to determine the sentiment or emotional tone behind it.
- Question answering: LLMs can answer questions based on the text they have been trained on.
- Personalized Learning on Autopilot: Every student learns differently. LLMs can tailor the learning experience to individual needs. They can generate customized practice problems, provide explanations in a way that resonates with each student’s learning style, and even offer feedback that helps them improve.
Benefits of Large Language Models:
LLMs have many benefits, including:
- Improved language understanding: LLMs can help computers understand language more like humans do.
- Increased productivity: LLMs can automate tasks such as translation and summarization, freeing up humans to focus on more creative tasks.
- Enhanced customer experience: LLMs can power chatbots that can provide 24/7 customer support.
- Access to information: LLMs can provide access to information for people who may not have been able to access it before, such as language barriers.
Challenges of Large Language Models:
While LLMs have many benefits, they are not without their challenges. Addressing these challenges is crucial for the responsible development and deployment of these powerful AI tools, including:
Data Privacy and Security: LLMs are trained on vast amounts of data, some of which may include sensitive information. Ensuring that user data is handled responsibly and protected against breaches is a significant concern. Models must be designed to avoid inadvertently learning and regurgitating personal data, maintaining strict privacy standards.
Bias in LLMs: They might inadvertently learn and reflect biases that are in the data. These can take different forms, like reinforcing stereotypes or unfairly disadvantaging certain groups. The development of methods to detect, and prevent bias is an ongoing challenge and requires continuous effort and Creativity.
Resource Intensity: Resource Intensity Training LLMs is computationally intensive, with significant energy and resources invested. This brings up important environmental concerns about the carbon footprint of developing and running these models. Making LLMs more efficient and finding ways for more sustainable AI practices will be necessary.
Scalability and Deployment: LLMs must respond to deployment challenges related to scalability, latency, and cost in real-world applications. Making sure that such models can run within an environment, from cloud infrastructure down to edge devices, efficiently and effectively will be paramount for their wide adoption.
Continuous Learning and Adaptation: As language and societal norms change, so too must LLMs to remain relevant and representative. The opportunity of continuously building learning methods and updating the models without much retraining is a big deal. That is, in the long term, it is very important to check if the models stay up to date and aligned with current knowledge and values.
Using LLMs for Text Generation:
Here is a detailed tutorial on using Large Language Models (LLMs) for text generation:
Step 1: Install the Hugging Face Transformers Library
The Hugging Face Transformers library provides pre-trained models and easy-to-use interfaces for working with LLMs. You can install it using pip:
pip install transformersStep 2: Load a Pre-Trained LLM
Load a pre-trained LLM using the AutoModel class:
from transformers import AutoModel
model = AutoModel.from_pretrained("gpt-3.5-turbo")This loads the GPT-3.5-Turbo model, which is a popular LLM. You can choose from many other pre-trained models, such as BERT, RoBERTa, and XLNet.
Step 3: Prepare Input Text
Prepare some input text to generate a response:
input_text = "Hello, I'm looking for a restaurant recommendation in New York City."You can also add additional parameters to the input text, such as:
input_text = {
"input": "Hello, I'm looking for a restaurant recommendation in New York City.",
"parameters": {
"max_length": 100,
"num_return_sequences": 1,
"temperature": 1.0
}
}This adds parameters for the maximum length of the generated text, the number of return sequences, and the temperature (which controls the randomness of the generation).
Step 4: Generate Text
Use the generate method to generate text based on the input:
output_text = model.generate(**input_text)This generates a response up to 100 characters long. You can adjust the parameters to control the generation process.
Step 5: Print the Output
Print the generated text:
print(output_text)This will print a response like:
"Here's a recommendation: try Carbone, an Italian-American restaurant in Greenwich Village. Enjoy!"Step 6: Experiment with Different Models and Inputs
Try using different pre-trained models and input texts to see how the output changes. You can also experiment with different parameters, such as max_length and num_return_sequences, to control the generation process.
Additional Tips:
- You can use the tokenizer attribute of the model to tokenize the input text before generation.
- You can use the generate method with different parameters, such as do_sample=True to generate multiple responses.
- You can use the batch_generate method to generate text for multiple input texts at once.
Here is the complete example code:
from transformers import AutoModel
# Load pre-trained model
model = AutoModel.from_pretrained("gpt-3.5-turbo")
# Prepare input text
input_text = {
"input": "Hello, I'm looking for a restaurant recommendation in New York City.",
"parameters": {
"max_length": 100,
"num_return_sequences": 1,
"temperature": 1.0
}
}
# Generate text
output_text = model.generate(**input_text)
# Print output
print(output_text)Here are ten of the best LLMs in 2024
- GPT: OpenAI’s Generative Pre-trained Transformer (GPT) models are the most famous tools that use an LLM.
- Gemini: Google’s family of AI models is designed to operate on different devices
- Llama 3: This family of open LLMs is from Meta, the parent company of Facebook and Instagram.
- Vicuna: This open chatbot is built off Meta’s Llama LLM.
- Claude 3: This is arguably one of the most important competitors to GPT.
- Stable Beluga and StableLM 2: Stability AI’s handful of open LLMs are based on Llama.
- Coral: Cohere’s Coral LLM is designed for enterprise users.
- Falcon: This family of open LLMs can outperform older models like GPT-3.5 in some tasks.
- DBRX: Databricks’ DBRX LLM is the successor to Mosaic’s MPT-7B and MPT-30B LLMs.
- XGen-7B: Salesforce’s XGen-7B performs about as well as other open models with seven billion parameters.
Conclusion:
In this blog post, we explored the exciting world of Large Language Models (LLMs) and their applications in text generation. We learned how to use the Hugging Face Transformers library to load pre-trained LLMs, prepare input text, generate text, and experiment with different models and inputs.
LLMs have completely transformed how computers handle human language, allowing them to understand and produce text that feels incredibly human-like. Their uses are incredibly diverse, ranging from creating chatbots and generating content to translating languages and analyzing emotions.
By following this tutorial, you’ve not only learned about LLMs but also gained practical experience with them. Now, you’re equipped to dive into your own projects and explore the vast potential of LLMs. Don’t hesitate to experiment with different models, inputs, and settings to unlock all the amazing things LLMs can do.
.png&description=The Era of Large Language Models ){kind=link}